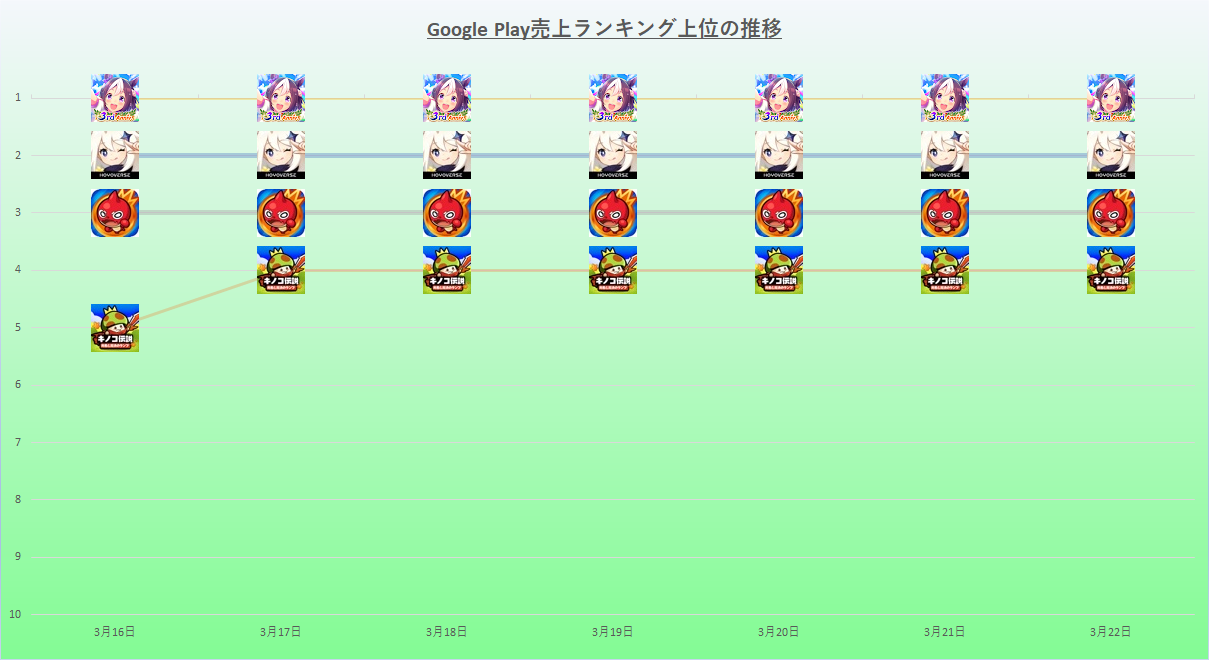
一般社団法人コンピュータエンターテインメント協会(CESA)が、8月30日~9月1日までパシフィコ横浜にて開催した、国内最大のゲーム開発者向けカンファレンス「コンピュータ・エンターテインメント・デベロッパーズ・カンファレンス 2017」(CEDEC 2017)。
本稿では、9月1日に実施された講演「キャラクターらしさ学習AI:多数のキャラクターの個性や違いの可視化によるシナリオライティング支援システム事例」についてのレポートをお届けしていく。 本セッションでは、株式会社Cygamesのリサーチャー・都築圭太氏が登壇。キャラらしさ学習AIの詳細と、実際にトレーニングツールとして導入した際に得られた知見の紹介が行われた。

▲株式会社CygamesのCygames Research リサーチャー・都築氏。30本を超えるミニゲームを取りまとめる部署のエンジニアリーダーを務めた後、2016年よりCygames Researchにて研究開発に従事。現在は主にゲームのテキストデータを対象とした自然言語処理技術の開発に取り組んでいる。
ゲームの開発・運営において、魅力的なキャラクターを表現するシナリオは極めて重要となる。しかし、新人からベテランまで異なる熟練度のライターチームが組織的・効率的に一貫性を持ってシナリオを執筆することは容易ではない。そこで、Cygamesではシナリオ文におけるキャラクターらしさを、その「話し方・口癖」と、「発話内容・好む話題」の2つの側面から学習するAIと、そのAIを利用するライティング支援システムを開発した。
本セッションでは、まず都築氏がサマリを発表。既存の膨大なキャラクターセリフのテキストから、その特定の「キャラクターらしさ」を学習して自動判定するAIを用いて、新規セリフを自動チェック。そうすることで、監修者への負荷を減らし、チーム全体でのクオリティと開発スピードの向上を実現したという。
監修タスクの大きな課題は、多人数で継続的にシナリオ(セリフ)を執筆するときに、キャラクターの性格、興味、口調などのテキスト上に現れる“らしさ”の一貫性を、チームとして保証していくことである。簡単に言えば、同じキャラクターであっても、ライターによって性格や口調が微妙に変わる、という事態を防がなければならない。この監修をAIでサポートする場合、キャラクターという仮想的な存在の個性を学習し、テキストがその個性を示すセリフとして適しているか評価する技術が必要である。

▲AIのサポートで解決される問題点。
学習AIの概要は、キャラクターの個性を生み出す要因を入力データから学習し、ユーザが指定した分析方法に従って可視化するというもの。学習AIへの入力データは、名前とセリフを縦に並べたシンプルな形式のため、少ない工数で既存の資源を活用できる。たとえば、エクセルでまとめられたシナリオデータをマクロなどでCSVに変換、それを学習AIに入力していく形となる。
実際に“キャラクターらしさ”の要素を抽出するにはどうすれば良いのか。本システムでは、キャラクターの特徴を「話し方・口癖」と「発話内容・好み」の2つの側面から抽出する。内容は下記の通り。
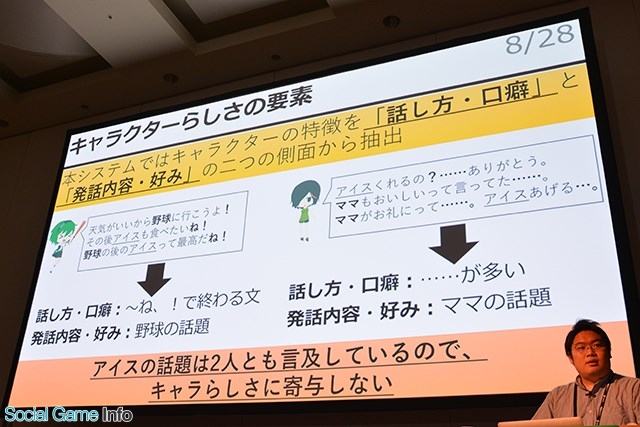
▲2人のキャラクターの会話から、話し方・口癖、発話内容・好みを抽出。アイスはキャラクターの個性に寄与しない。
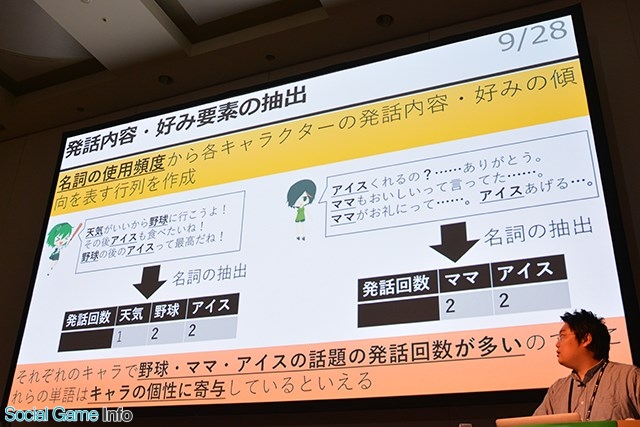
▲名詞を抽出して、その使用頻度からキャラクターの発話内容・好みの傾向を分析する。

▲話し方や口癖要素を網羅的に抽出。セリフの部分文字列を使用し、出現回数が多いものを、そのキャラクターの話し方や口癖としてカウントする。
では、これらを用いて実際にどういう分析ができるのか。都築氏は執筆支援例として、「お嬢様キャラ」の新しいセリフを作りたいが、同じタイトルの他キャラに寄りすぎていないか知りたい、という状況を想定したものを説明。たとえば、「冷たい紅茶をお願いできるかしら?」というセリフを分析する場合、学習データとして仮に「sample_narrative.csv」を分析対象に指定する。すると先程のセリフがグラフ化され、お嬢様、ミステリアス、ゆるふわなどの属性のうち、どの要素が一番強いか、つまりどういったキャラクターらしさがあるかが視覚的に分かるようになる。


▲グラフ上では「お嬢様」が1位になっており、2位との差も大きい。先程のセリフは総合的に「お嬢様キャラ」であるといえる。
現在のシステムでは、発話内容のみをカウントしているため、過去に言っていないセリフは関係がないと見なされる。これが問題であると都築氏。例えば、先程の例にある「冷たい紅茶をお願いできるかしら?」の「紅茶」の部分を「ミルクティー」に変えた場合、前者と後者の名詞はキャラらしさにおける違いはほぼない。しかし、システム上では関連がないと判断されてしまう可能性がある。この問題を解決すべく、特徴抽出精度を向上されるため、セリフから抽出された特徴行列と異なるドメインのデータ統合を、行列で外部知識を表現することで可能にしたという。
外部データには、豊富な情報量をもち、単語の関連をリンクとして保持するWikipediaを使用。単語間の距離をリンク数を図ることで、単語間の関数速度を表す行列を作成。リンク構造に対して固有値分解という処理を行うことにより、「他の記事の説明に使用されるような一般的な単語」の度合いを測定している。
また、「言っていてもおかしくない単語」をキャラと関連付けるために、単語関連度を用いて実発話していない単語の仮想発話回数をカウント。たとえば、先程のお嬢様キャラが「紅茶」を2回発話した場合を想定する。「レモンティー」は「紅茶」と関連があるため、「紅茶」1回の発話につき0.5回分の発話として計算。結果として「レモンティー」と言及したことがなくても、関連単語である「紅茶」を2回発話しているので、「レモンティー」を1回発話したものとみなす、というものだ。
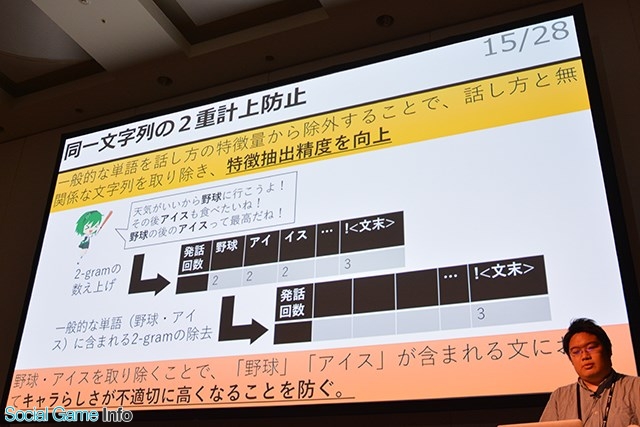
▲一般的な単語を話し方の特徴量から除外。たとえば上の写真の場合、話し方の特徴とは関係のない野球とアイスを除外し、“キャラらしさ”の精度を上げている。
次に、差別化への寄与度の評価について。寄与度は「要素の発話頻度」と「要素の発話者数」から決まる。どのキャラ間を比較すべきかという分析者の視点を分析者に反映できるという。例は下記の通り。

▲分析対象を2タイトルのセリフを混ぜたデータに変更。他タイトルの他キャラと被っていないかをチェックできる。
また、データ・キャラ選択基準をAI使用者の需要に合わせて変化させるため、独自開発したスプリクト言語で記述された内容に従って、分析内容を動的に選択できる。簡単に言えば、1つのセリフをデータに入っているキャラ全員と比較する、また2~3人だけ選択して比較するということもできるというわけだ。例えば、新人ライターに2人の頭脳派キャラの違いがどこにあるか理解してもらいたい場合。「それは興味深い戦略だな」「それは興味深い実験だな」という2つのセリフを使用し、“戦略”と“実験”どちらに反応があるかを調べる。このように“キャラらしさ”の精度を上げる判断材料として使用できるわけだ。
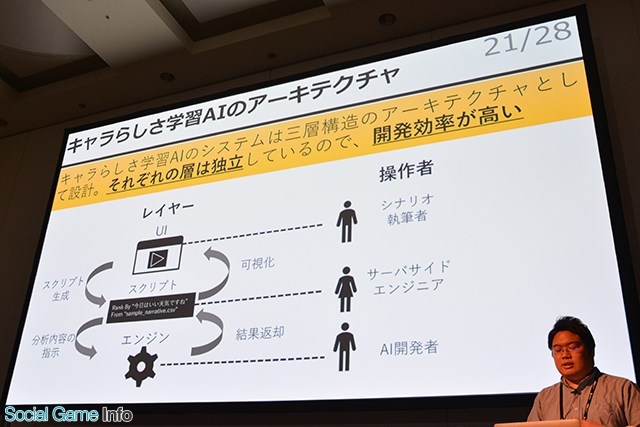
▲本システムは、UI、スプリクト、エンジンの三層構造のアーキテクチャとして設計。
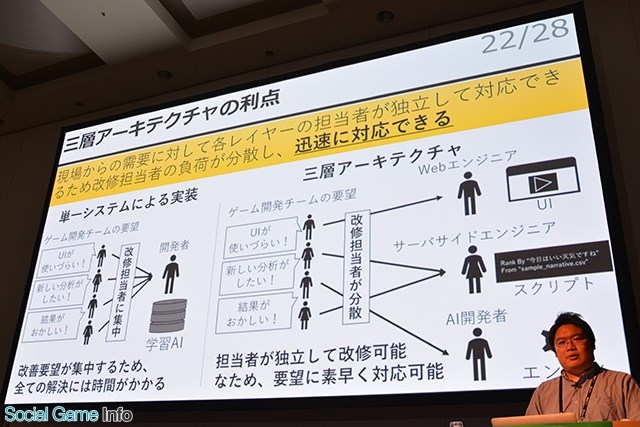
▲三層アーキテクチャにすることで、担当者がそれぞれ独立して改修が可能であるため、開発チーム要望に素早く対応ができる。
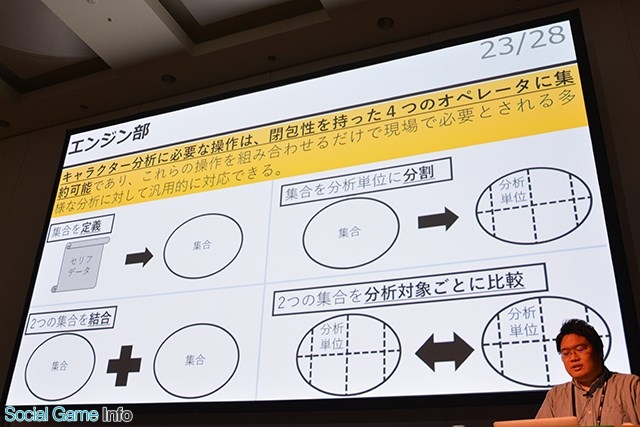
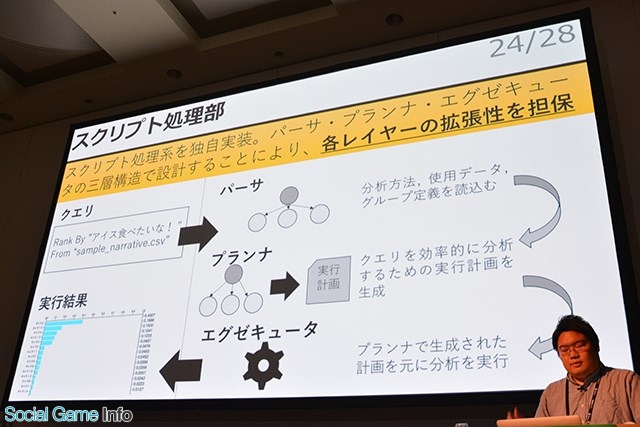
▲エンジン部とスプリクト処理部について。
まとめとして、キャラクター間の差別化要素を学習する“キャラらしさ学習AI”の導入により、ライター自身による制作物の定量評価を実現し、監修者への負荷集中を緩和、さらに入力したセリフがキャラらしいセリフになっているか、ほかキャラとの差別化はなされているかを可視化できる。つまり、組織的シナリオライティングにおけるワークフローの効率化・品質向上を実現できると説明し、本セッションを締めた。
本稿では、9月1日に実施された講演「キャラクターらしさ学習AI:多数のキャラクターの個性や違いの可視化によるシナリオライティング支援システム事例」についてのレポートをお届けしていく。 本セッションでは、株式会社Cygamesのリサーチャー・都築圭太氏が登壇。キャラらしさ学習AIの詳細と、実際にトレーニングツールとして導入した際に得られた知見の紹介が行われた。
▲株式会社CygamesのCygames Research リサーチャー・都築氏。30本を超えるミニゲームを取りまとめる部署のエンジニアリーダーを務めた後、2016年よりCygames Researchにて研究開発に従事。現在は主にゲームのテキストデータを対象とした自然言語処理技術の開発に取り組んでいる。
ゲームの開発・運営において、魅力的なキャラクターを表現するシナリオは極めて重要となる。しかし、新人からベテランまで異なる熟練度のライターチームが組織的・効率的に一貫性を持ってシナリオを執筆することは容易ではない。そこで、Cygamesではシナリオ文におけるキャラクターらしさを、その「話し方・口癖」と、「発話内容・好む話題」の2つの側面から学習するAIと、そのAIを利用するライティング支援システムを開発した。
本セッションでは、まず都築氏がサマリを発表。既存の膨大なキャラクターセリフのテキストから、その特定の「キャラクターらしさ」を学習して自動判定するAIを用いて、新規セリフを自動チェック。そうすることで、監修者への負荷を減らし、チーム全体でのクオリティと開発スピードの向上を実現したという。
監修タスクの大きな課題は、多人数で継続的にシナリオ(セリフ)を執筆するときに、キャラクターの性格、興味、口調などのテキスト上に現れる“らしさ”の一貫性を、チームとして保証していくことである。簡単に言えば、同じキャラクターであっても、ライターによって性格や口調が微妙に変わる、という事態を防がなければならない。この監修をAIでサポートする場合、キャラクターという仮想的な存在の個性を学習し、テキストがその個性を示すセリフとして適しているか評価する技術が必要である。
▲AIのサポートで解決される問題点。
学習AIの概要は、キャラクターの個性を生み出す要因を入力データから学習し、ユーザが指定した分析方法に従って可視化するというもの。学習AIへの入力データは、名前とセリフを縦に並べたシンプルな形式のため、少ない工数で既存の資源を活用できる。たとえば、エクセルでまとめられたシナリオデータをマクロなどでCSVに変換、それを学習AIに入力していく形となる。
実際に“キャラクターらしさ”の要素を抽出するにはどうすれば良いのか。本システムでは、キャラクターの特徴を「話し方・口癖」と「発話内容・好み」の2つの側面から抽出する。内容は下記の通り。
▲2人のキャラクターの会話から、話し方・口癖、発話内容・好みを抽出。アイスはキャラクターの個性に寄与しない。
▲名詞を抽出して、その使用頻度からキャラクターの発話内容・好みの傾向を分析する。
▲話し方や口癖要素を網羅的に抽出。セリフの部分文字列を使用し、出現回数が多いものを、そのキャラクターの話し方や口癖としてカウントする。
では、これらを用いて実際にどういう分析ができるのか。都築氏は執筆支援例として、「お嬢様キャラ」の新しいセリフを作りたいが、同じタイトルの他キャラに寄りすぎていないか知りたい、という状況を想定したものを説明。たとえば、「冷たい紅茶をお願いできるかしら?」というセリフを分析する場合、学習データとして仮に「sample_narrative.csv」を分析対象に指定する。すると先程のセリフがグラフ化され、お嬢様、ミステリアス、ゆるふわなどの属性のうち、どの要素が一番強いか、つまりどういったキャラクターらしさがあるかが視覚的に分かるようになる。
▲グラフ上では「お嬢様」が1位になっており、2位との差も大きい。先程のセリフは総合的に「お嬢様キャラ」であるといえる。
現在のシステムでは、発話内容のみをカウントしているため、過去に言っていないセリフは関係がないと見なされる。これが問題であると都築氏。例えば、先程の例にある「冷たい紅茶をお願いできるかしら?」の「紅茶」の部分を「ミルクティー」に変えた場合、前者と後者の名詞はキャラらしさにおける違いはほぼない。しかし、システム上では関連がないと判断されてしまう可能性がある。この問題を解決すべく、特徴抽出精度を向上されるため、セリフから抽出された特徴行列と異なるドメインのデータ統合を、行列で外部知識を表現することで可能にしたという。
外部データには、豊富な情報量をもち、単語の関連をリンクとして保持するWikipediaを使用。単語間の距離をリンク数を図ることで、単語間の関数速度を表す行列を作成。リンク構造に対して固有値分解という処理を行うことにより、「他の記事の説明に使用されるような一般的な単語」の度合いを測定している。
また、「言っていてもおかしくない単語」をキャラと関連付けるために、単語関連度を用いて実発話していない単語の仮想発話回数をカウント。たとえば、先程のお嬢様キャラが「紅茶」を2回発話した場合を想定する。「レモンティー」は「紅茶」と関連があるため、「紅茶」1回の発話につき0.5回分の発話として計算。結果として「レモンティー」と言及したことがなくても、関連単語である「紅茶」を2回発話しているので、「レモンティー」を1回発話したものとみなす、というものだ。
▲一般的な単語を話し方の特徴量から除外。たとえば上の写真の場合、話し方の特徴とは関係のない野球とアイスを除外し、“キャラらしさ”の精度を上げている。
次に、差別化への寄与度の評価について。寄与度は「要素の発話頻度」と「要素の発話者数」から決まる。どのキャラ間を比較すべきかという分析者の視点を分析者に反映できるという。例は下記の通り。
▲分析対象を2タイトルのセリフを混ぜたデータに変更。他タイトルの他キャラと被っていないかをチェックできる。
また、データ・キャラ選択基準をAI使用者の需要に合わせて変化させるため、独自開発したスプリクト言語で記述された内容に従って、分析内容を動的に選択できる。簡単に言えば、1つのセリフをデータに入っているキャラ全員と比較する、また2~3人だけ選択して比較するということもできるというわけだ。例えば、新人ライターに2人の頭脳派キャラの違いがどこにあるか理解してもらいたい場合。「それは興味深い戦略だな」「それは興味深い実験だな」という2つのセリフを使用し、“戦略”と“実験”どちらに反応があるかを調べる。このように“キャラらしさ”の精度を上げる判断材料として使用できるわけだ。
▲本システムは、UI、スプリクト、エンジンの三層構造のアーキテクチャとして設計。
▲三層アーキテクチャにすることで、担当者がそれぞれ独立して改修が可能であるため、開発チーム要望に素早く対応ができる。
▲エンジン部とスプリクト処理部について。
まとめとして、キャラクター間の差別化要素を学習する“キャラらしさ学習AI”の導入により、ライター自身による制作物の定量評価を実現し、監修者への負荷集中を緩和、さらに入力したセリフがキャラらしいセリフになっているか、ほかキャラとの差別化はなされているかを可視化できる。つまり、組織的シナリオライティングにおけるワークフローの効率化・品質向上を実現できると説明し、本セッションを締めた。
(文・長戸勲)