




【CEDEC 2020】DeNA、『逆転オセロニア』におけるバンディットアルゴリズムと強化学習を用いた対戦環境のバランス設計支援

コンピュータエンターテインメント協会(CESA)は、9月2日~4日の期間、オンラインにて、国内最大のゲーム開発者向けカンファレンス「コンピュータ・エンターテインメント・デベロッパーズ・カンファレンス 2020」(CEDEC 2020)が行われた。
本稿では、9月3日にディー・エヌ・エー(DeNA)<2432>が実施したセッション「『逆転オセロニア』における,バンディットアルゴリズムおよび強化学習を用いた対戦環境のバランス設計支援」の模様をお届けする。
このセッションに、ゲーム・エンターテインメント事業本部 ゲーム事業部 Publish統括部 AI推進部の吉村拓真氏と、AI本部AIシステム部 AI研究開発エンジニアの甲野佑氏が登壇。
『逆転オセロニア』における「教師あり学習」「クラスタリング×バンディットアルゴリズム」、そして「強化学習」の手法を併用した、キャラ・デッキアーキタイプのバランス設計の支援機構及びゲーム運用への導入について語られた。
まずは吉村氏が、『オセロニア』におけるAI関連の取り組みについて紹介。
オセロをモチーフとし、プレイヤーは駒(キャラクター)の能力と自身のオセロ力を駆使して勝利を目指す本作は、PvPが主体であり、対戦環境は深みを増し続け、現在はそのバランス調整に力を入れているとした。
「強化学習によって対戦環境のバランス調整の貢献を目指している」と吉村氏。
これまで活用していたAIは、"教師あり学習"によるものだったが、それだけでは対戦環境のバランス調整に対しては不十分。
強化学習が有効であろうと判断し、導入に踏み切ったそうだ。
しかし、強化学習は各種学習手法と比べ難易度が高く、プロダクトにおける実ユースケースの定義が難しかったり、学習に数日を要する上に学習後の強度が中々安定しない等の課題を抱えているとした。
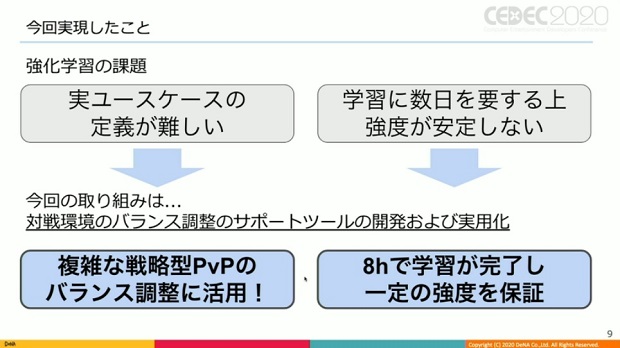
そうした前提の中で、強化学習により対戦環境のバランス調整をサポートすツールを開発、実用化した。
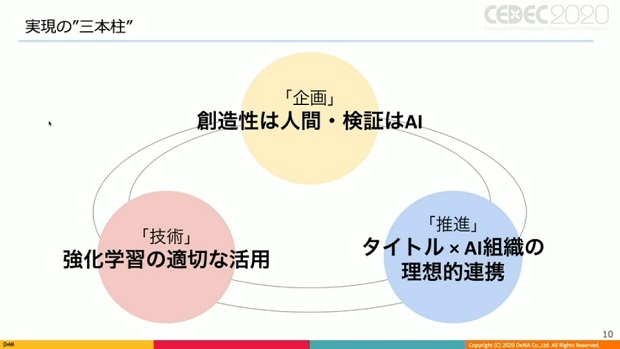
▲案件を進める上で重要だった3つのポイント。
ここまでの話を踏まえ、吉村氏は『オセロニア』における過去のAI活用事例に触れた。

▲過去の活用事例はいずれも対戦をより多くのプレイヤーに楽しんでもらいたいという思いに根差している。
一方で、『オセロニア』の運営が続くにつれキャラ数も増え続け、現在4000種類を超えているという。
「それに伴い対戦環境は複雑さを増し、対戦環境のバランス調整自体の難易度が上昇してきているのも実情」と吉村氏。
バランス調整の失敗は対戦環境の面白みを損ない、プレイヤーを楽しませる事が根本的に難しくなるため、AIでの課題解決を目指した。
対戦環境のバランス調整は、その大部分が新規キャラのリリースによって行われるという。新規キャラの属性やHP、攻撃力、スキル等のパラメーター、投入するデッキタイプの傾向により、対戦環境は姿を変えていく。
つまり、新規キャラが対戦環境にどのような影響を及ぼすのかを事前に意識してキャラ設計してリリースする事によって、対戦環境のバランス調整が行われていく事になる。
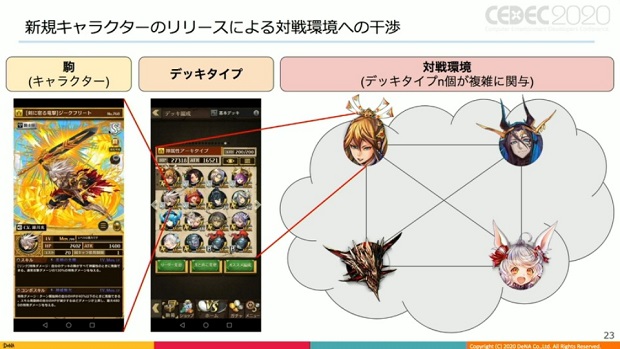
新規キャラが対戦環境に及ぼす影響を事前に正確に把握する直接的な方法は、極論だが、そのキャラを様々なデッキに導入し、ありとあらゆるパターンでテストプレイする事。

上図の数字は、4000種類のキャラから重複なく16種類を選択した時のデッキの組み型のパターン数の概算である。
「この数字の大きさだけでも、現在のパターンを網羅的に検証する事は事実上不可能」と吉村氏。従って、実際にはテストプレイ対象をより絞り込んでいく工程が必要とのこと。
しかし、絞り込む程にテストから漏れたパターンにおいて想定外の問題が発生するリスクが上昇。時間的な制約から、主流デッキタイプでのテストプレイさえ網羅できていないのが実情だ。
また、キャラ設計業務で設計者の熟練度に強く依存するという課題も。熟練度が低いと、設計案の作成、検証における精度が低下したり、評価の判断を誤る等の問題が発生する恐れがあり、対戦環境のバランスを棄損するリスクが高まるという。
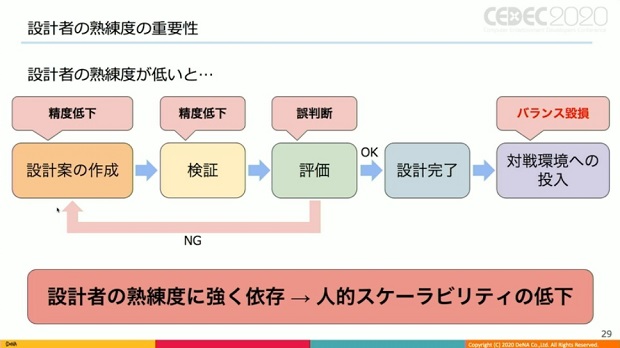
そこで吉村氏は、AIによる課題解決を試みた。設計案作成と評価を人間が、検証をAIが分担して行うイメージだ。
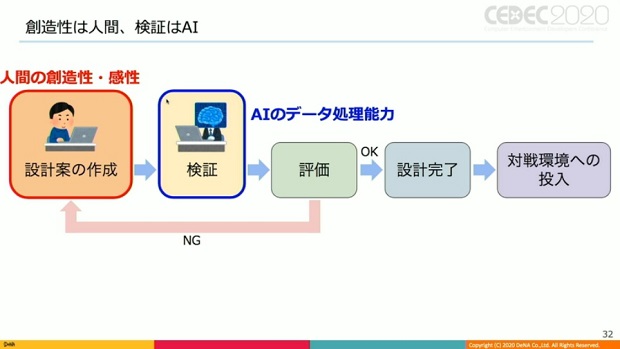
▲創造性や感性を要求する作業は人間、大量データの処理能力が有用に働く作業はAIが行うという考え方。
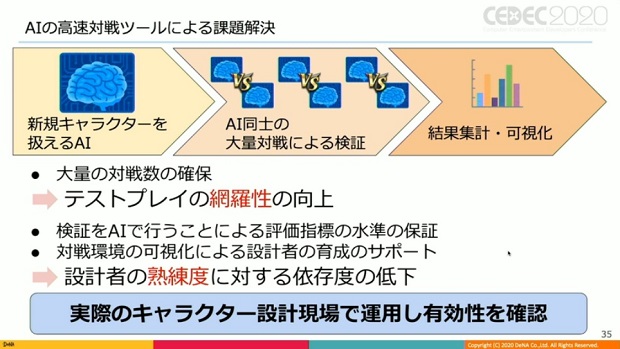
▲こちらが具体的なアプローチの概要。
この手法により、「大量の対戦数の確保と、それに伴うテストプレイの網羅性の向上が期待できる」と吉村氏。
また、検証をAIが行う事で、評価指標の水準を一定保証し、対戦環境の可視化データを設計者育成のサポートに利用する事で、「設計者の熟練度に対する依存度を低下させる効果も見込まれる」とした。
■本案件に用いたAI技術
続いて登壇した甲野氏は、「強化学習に全て任せない事」を本件で大切にしたコンセプトと前置きし、今回用いたAI技術に関して解説。
強化学習は難しい技術のため、課題を切り分け、使用箇所を適切に限定することで実用化した。
具体的にはフルスペックな強化学習を用いるのではなく、既存の教師ありAIとバンディットアルゴリズムをトリッキーに組み合わせたという。
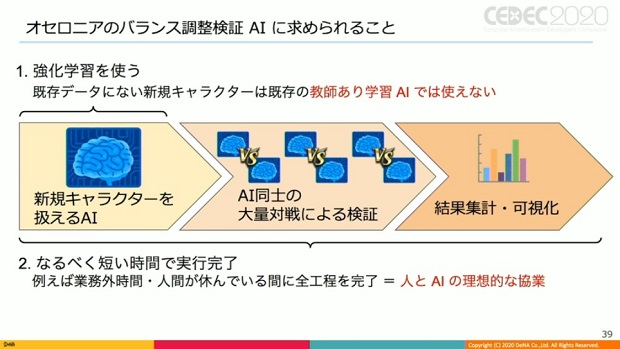
『オセロニア』のバランス調整検証AIに求められた案件は、既存データにない新規キャラは教師ありAIでは使えないため、強化学習関連技術を使って実現する事。
もう1つは、なるべく短い時間で実行完了する事だ。
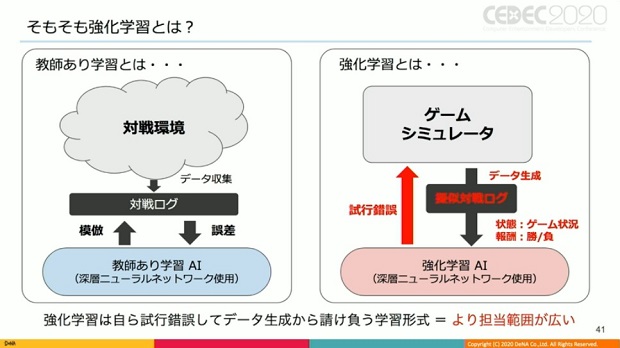
▲教師あり学習と強化学習について。
データ生成・収集を自ら行う強化学習は万能なAIを目指した技術で、学習コストや難易度の高さから実プロジェクトに使いづらいとされる。
そこで甲野氏は、「全てを強化学習に任せるのではなく、問題を簡略化、工夫することで他の教師ありAI等と組み合わせる事で実現できるのでは」と考えた。
次に、実際に課題をどう分解すればい良いか、バランス調整AIのユースケースを紹介。
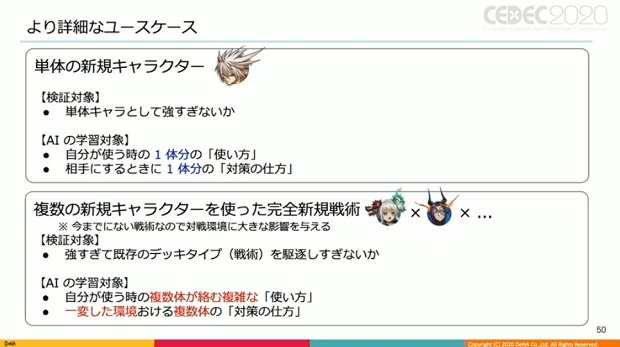
単体の新規キャラはその使い方、敵になった時の対策を考えれば良いが、複数の新規キャラを使った完全新規戦術の場合は、複数体が絡む複雑な戦術を学習し、それによって変化した環境も含めた対策を学習する必要がある。
両者には明らかな難易度の差があるが、逆に前者は高頻度なので低コストな手法を、後者は高コストな手法を使う事でオーバースペックを回避し、適切に運用が可能ではないかと考えられる。
甲野氏は、従来の教師ありAIも含め、具体的なAI構成について触れた。
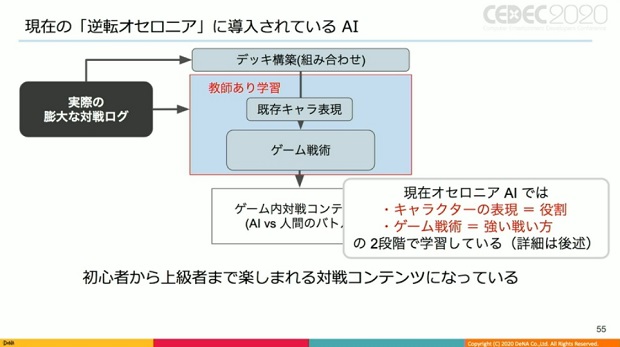
▲簡略化されているが、現在の『オセロニア』に導入されている教師ありAI。最大の工夫は、キャラの役割と、役割を用いた強い戦術の2段階で学習している点。
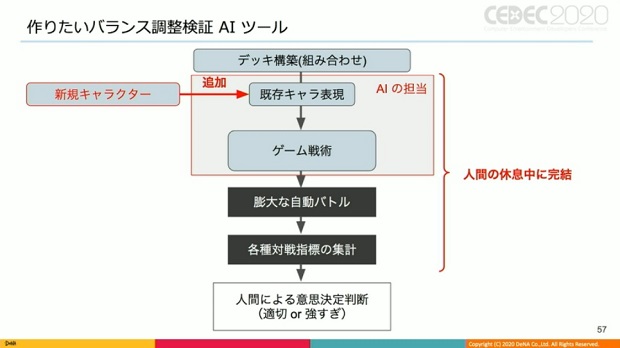
▲それに対し、今回扱うバランス調整検証AI。人間の休息中に膨大な自動バトルや対戦指標の集計などを完結させる必要がある。
上のAI構成を丸々強化学習に置き換えたい、というのが本音だが、全てを強化学習で実行するのは難しく、学習時間も長引き、人間が眠っている間に完結しない、というのが現実的とのこと。
そこで甲野氏は、先の2つのユースケースに合わせた2つのAI構成を考えた。
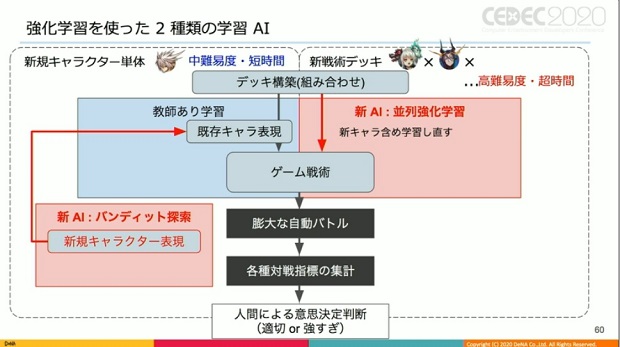
まず単体キャラに関するAI構成。最大の工夫点は、既存キャラに対し、新規キャラは単体キャラの使い方、キャラクター表現に学習対象を限定し、ここに強化学習関連技術を使う事での低難易度化した事だ。
キャラクター表現とは何かというと、キャラ数分を自然言語由来の手法でキャラ固定の役割のようなものに埋め込み、AIの内部で扱われるもの。
これにより、キャラの役割が近い空間が形成され、近い役割が近い領域に集まるというキャラクター表現ベクトルが形成されるという。
このベクトルは数値的に近い程使い方が似ている事になり、新規キャラがどの領域に当てはまるかで使い方、キャラのポテンシャルとしての強さが判明。
従って、既存のベクトルから新規キャラがどこに当てはまるか探索できれば良いのではと考えた。
具体的には、キャラクター表現ベクトルをクラスタリングし、使い方が似ているクラスタを形成する事。
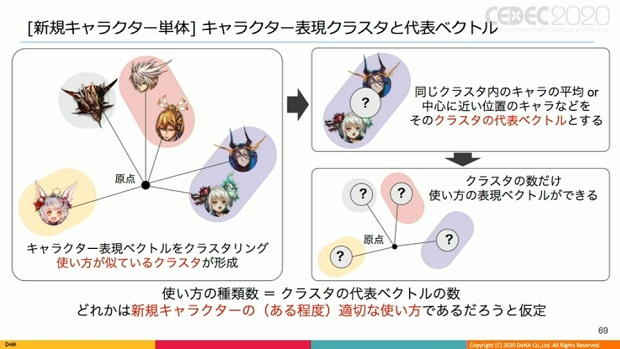
▲クラスタ内のキャラの平均、あるいは中心地点に一番近いキャラ等のアイデアから代表ベクトルを作る。
そうすることで、クラスタ数だけ使い方を代表するベクトルが形成できる。
クラスタを幾つに分けるかにもよるが、「このクラスタのどれかは、新規キャラを最も有効に使えると考え、それを探索する方法に問題を変換している」と甲野氏。
探索にはバンディットアルゴリズムを使っているとした。
バンディットアルゴリズムは非常に単純な強化学習の一種と言われており、例えば広告業界で使われているABテストの発展版のようなもの。
限られた回数の中で、なるべく最適化しようとするアルゴリズムであるため、「一晩の限られた時間内で実行しようとする今回の案件にフィットしていると言える」(甲野)。
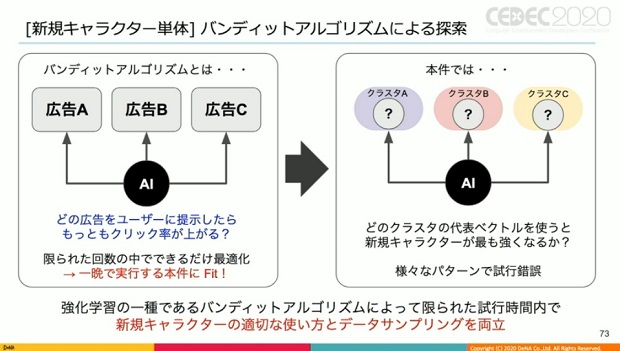
ここで1つ、『オセロニア』は単体キャラでは成立しないため、どのデッキに投入し、どのキャラと入れ替えたら強くなるか、という別の角度の問題が発生が、これもバンディットアルゴリズムで探索したという。
方法は、クラスタと広告の部分を既存キャラのどれを抜くか、という点を置き換えただけ。
こうすることで、新規キャラの表現を探索しながら、どのキャラと入れ替えて、どのデッキに入れるかという事も決めながら学習を進めることで、単体キャラとして強すぎないか、意外なデッキタイプとシナジーが生まれていないかを評価しているとした。
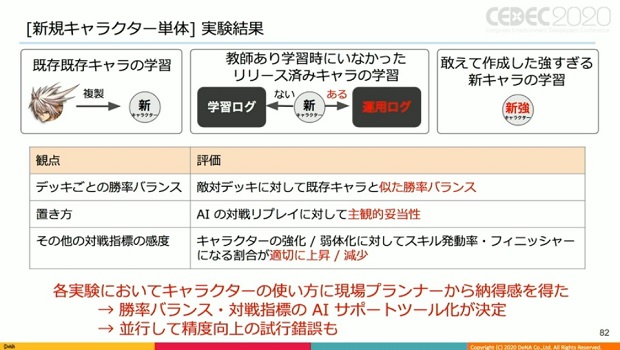
▲同ツールに関する新規キャラ単体の実験結果。勝率バランスや対戦指標についてのAIサポートツールの実装が決定した。
一方で、新戦術、複数キャラを使った戦術に関しては、新規キャラだけでなく過去のキャラの使い方も微妙に変わってしまうため、全てを学習し直す必要がある。
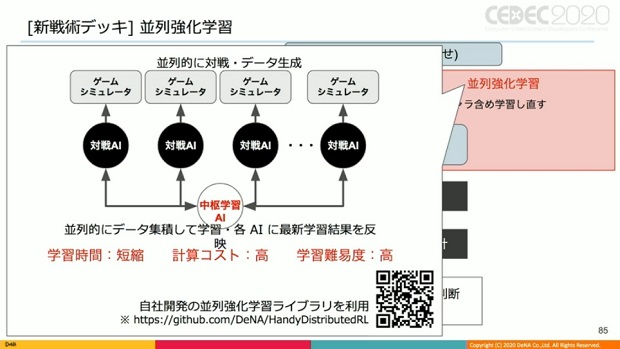
そこで甲野氏は、並列的にデータ集積して学習・各AIに最新学習結果を反映させる手法を使った。
しかし並列強化学習は、並列的にデータ生成する関係上、学習時間そのものは見かけ上短縮しているが、計算コスト、学習難易度も高い技術だった。
そこで自社ライブラリを開発することによって、学習を行ったという。
甲野氏は「対戦結果の評価のイメージは、実際ここまで至っていませんが」と前置きしつつ、新戦術デッキが旧来デッキに対してどのくらい強いか、それによって対戦戦術、特定の戦術を駆逐し過ぎないかを評価対象としているとした。
また甲野氏は、ゼロからの学習と追加学習という形と、並列強化学習を行った形を比較。
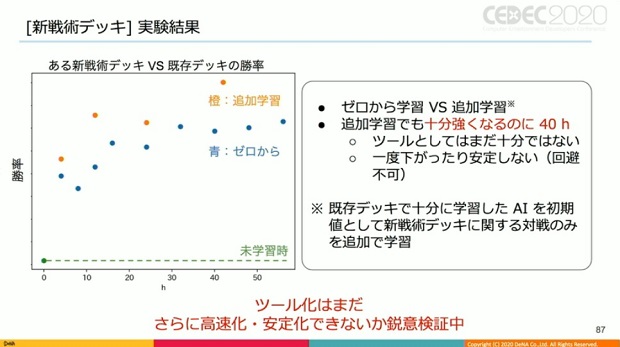
追加学習は、ある程度強化学習等で学習した状態から新戦術についてのみ学習を追加して行った場合、今回のケースではゼロから学習するより学習速度自体は早かったが、それでもトップの強さに至るまでに40時間程度かかったという。
「まだ十分ではないし、一度下がったり、まだ安定していません。こちらはまだツール化には至らず、さらなる高速化、安定化について鋭意検証中です」とコメントした。
■単体キャラに関するツール化と実用試験
ここから再び吉村氏が登壇。教師あり学習+バンディットアルゴリズムによる単体キャラの学習を採用したシステム化と実用試験について解説した。
AIによる大量対戦ツールのイメージだが、まず新規キャラを既存デッキタイプに入れ替える形で投入し、様々な組み合わせで対戦を繰り返す。
この時、対戦は教師あり学習によって既存キャラの使い方を学習済みのAI同士で行い、その過程でバンディットアルゴリズムによって新規キャラの扱い方を徐々に学習していく。
そして8時間の対戦を経た後、得られた大量の対戦ログから統計データを算出して可視化するというものだ。
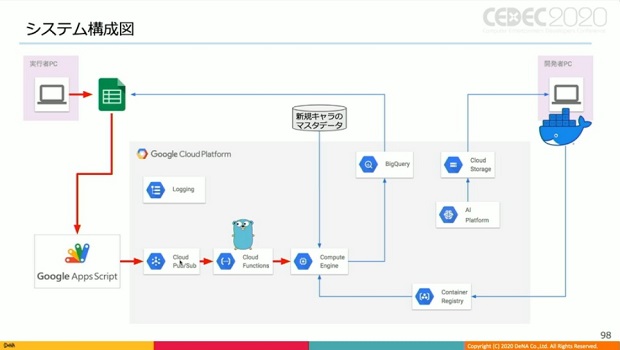
上図は実際のシステム構成図。まず使用者がスプレッドシートに必要なパラメーターを入力し、実行ボタンを押す。
するとGoogleアップスプリクト経由で、GCPのPub/Subに入力パラメーターが送信され、クラウドファンクションズが起動。そしてクラウドファンクションズがGCEのVMインスタンスを立ち上げる。
VMインスタンスの中ではドッカーコンテナが実行されているが、そのコンテナには予め教師あり学習済みのAIが内包されている。
また、VMインスタンスが外部から今回の検証対象のような新規キャラのマスタデータを引っ張ってくる。
こうして必要なものが全て揃ったら、VMインスタンス内の対戦シミュレーターによってAI同士の8時間の対戦が実行される。
そして8時間を経た後に得られた大量の対戦ログから算出された統計データがBigQueryに保存。
使用者はスプレッドシートにBigQueryから統計データの情報をロードすることで結果を閲覧する、という仕組みとなっている。

▲本ツールの運用手順。
システム構成で留意した点を吉村氏は「UIの簡便さとコストの低さ」と説明。
UIに関しては、使用者がパラメーター入力、実行、結果確認のインターフェースをスプレッドシートに集約しているが、「使用者となるプランナーが普段最も使い慣れているツールであると判断したため」と吉村氏。
また、「VMインスタンスは実行時に生成され、実行終了後に破棄される形でコストを抑制している」と加えた。
次にテストにおける各種パラメータ設定について、吸収スキルを持ち長期戦に長けている新規キャラを例に解説。
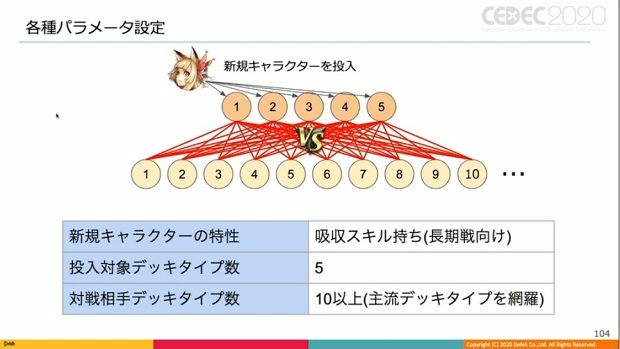
新規キャラが投入されたデッキタイプ数は5。主流デッキタイプ投入時に少しでもうまく扱える可能性があると思われるものをピックアップした結果だ。
一方、対戦相手に位置付けられるデッキタイプ数は10超。これは主流デッキタイプを一定網羅したものとなる。
そして下図が、8時間の実行を経て得られた統計データの1つ。新規キャラ投入により、従来と比較しての勝率の増減を表している。
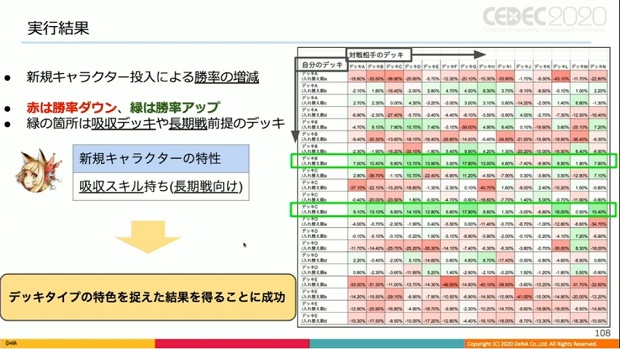
▲赤い箇所は勝率が低下、緑の箇所は上昇したこと示す。全体的に赤いが、一部横一列が緑の帯状に。つまり特定デッキタイプの特定キャラと入れ替えた場合のみ、様々なデッキタイプを相手に勝率が上昇していることを意味する。
この時、勝率上昇が顕著な箇所のデッキは、吸収デッキや長期戦前提の他デッキだった。即ち、今回試した新規キャラの特性に合致しており、比較的相性が良いデッキと言えるわけだ。
このことから「本ツールは各デッキタイプの特色を正しく捉え、結果を提示する事に成功している」と吉村氏は述べた。

▲本ツールの性能についていくつかの観点から評価。当初掲げた目的に対して一定の有効性が確認できたという。
続いて吉村氏は、ゲームAI案件の推進における課題と本案件において解決策となる独自の座組について紹介した。
吉村氏が従来携わってきたゲームAI案件は、AIを活用したいと考えるタイトルと、AI専門家チームによる案件単位の散発的な取り組みだったそうで、ゲーム事業全体の俯瞰的な視点や意志の不足、そして案件の性質上避けがたい進行の障壁の存在が課題とした。
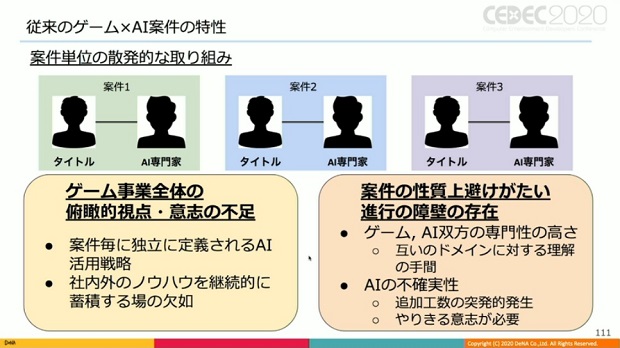
こうした課題を解決するため、ゲームAI案件全体のハブになるAI推進部が組織された。AI推進部が果たす主な役割は以下の3点。
・ゲーム事業の横断的なAI活用戦略の定義と、社内外のノウハウの蓄積及び横展開、スケーリングするゲーム事業全体によるAI活用の意思と戦略の確立
・タイトルとAI専門家のドメイン知識の差を埋め、コミュニケーションロスを軽減、円滑化
・AIそのものが持つ不確実性による突発的な工数需要の発生とボトルネック化に対応し、外部からの実働工数の供給を果たす実行力のプーリング
また、今回の案件における具体的な体制と役割分担を、進行するフェーズを分けて紹介した。
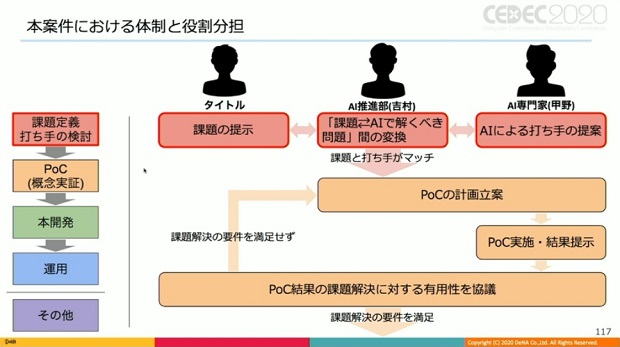
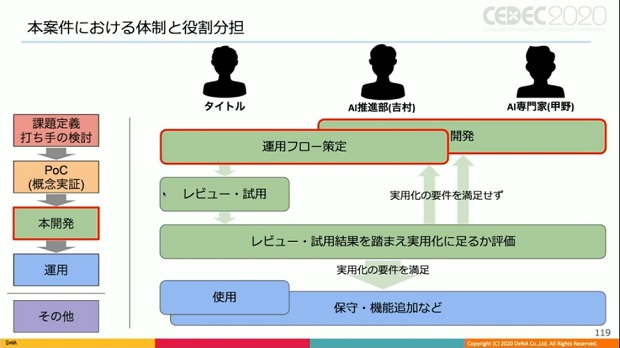
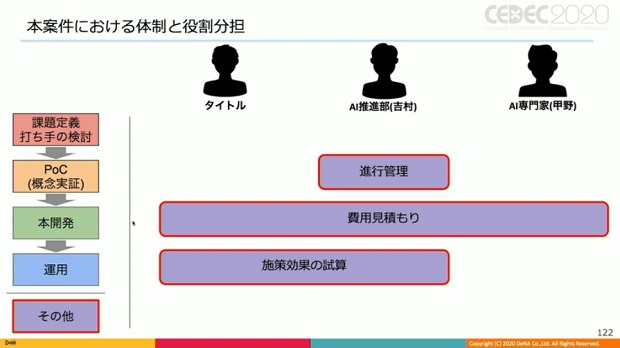
これら役割分担により、体系的、持続的なAI活動を可能とする構造的な強みの獲得を目指しているとした。
そして今後の展望について「創造性は人間、検証はAIという観点から、AI活用範囲を今後より拡大し、人間の創造性を最大限発揮できる形を追求したい。加えて、並列強化学習による複数キャラや新規デッキタイプの一括学習機能をツールに搭載、これを実践投入したい」と吉村氏。
本プロジェクトにおいて開発したシステムや得られた知見等をゲーム事業全体の財産とし、他タイトルへの積極的な横展開、スケーリングを行っていきたいとした。
■『逆転オセロニア』
© 2016 DeNA Co.,Ltd.
オセロは登録商標です TM & Ⓒ Othello,Co. and Megahouse




会社情報
- 会社名
- 株式会社ディー・エヌ・エー(DeNA)
- 設立
- 1999年3月
- 代表者
- 代表取締役会長 南場 智子/代表取締役社長兼CEO 岡村 信悟
- 決算期
- 3月
- 直近業績
- 売上収益1477億円、営業利益186億9400万円、税引前利益257億6400万円、最終利益190億4800万円(2026年3月期)
- 上場区分
- 東証プライム
- 証券コード
- 2432