




チェスや将棋、囲碁といった伝統的なボードゲームで人工知能が人間の能力を完全に凌駕して、早くも数年が経つ。それまで人工知能によるゲーム学習は、ルールベースによるアプローチや大量のデータを必要とする教師あり学習が一般的だった。
2017年に誕生したDeepMind社の「AlphaZero」は、完全な白紙状態から自己対局のみによって、それら3つのゲームの戦略を学習し、わずか2時間で将棋、4時間でチェスの世界一に到達した。さらに、自身の前身である世界最強の囲碁AI「AlphaGo Zero」を打ち負かすまでに要した時間は、たったの8時間だった。
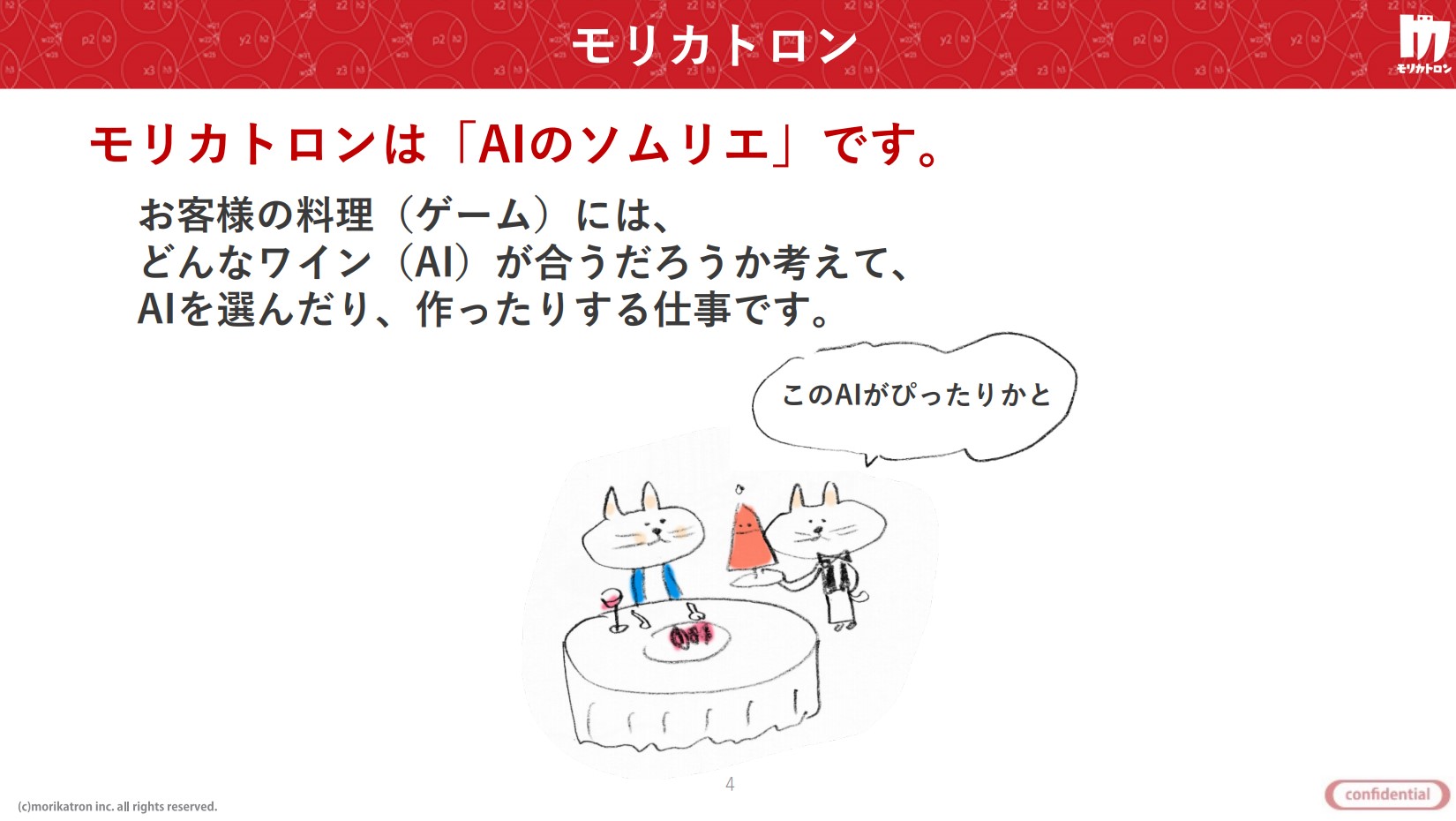
同年、日本初のゲームAI開発の専門企業として誕生したモリカトロン株式会社は、このAlphaZeroをベースに、完全情報ゲームに限らないゲームへ対応できる汎用型ボードゲームAIの研究に挑んでいる。ゲームという料理に合うAIというワインを選ぶ「AIソムリエ」を謳う同社は、教師なし学習の利点と将来性を検証することで、AIによる自律的な学習がゲーム開発業務にもたらす可能性やメリットを追求している。
その最終目標は、ビデオゲームの戦略獲得だ。9月4日からパシフィコ横浜で開催される国内最大のゲーム開発者向け技術交流会CEDECを前に、AIによる自律的な戦略獲得のノウハウを研究するモリカトロンの開発現場を取材した。
![]()
このセッションでは、AlphaZeroをベースに開発された同社オリジナルのAIモデル「モリカAI」を使ったボードゲーム学習の仕組みが披露されるほか、ボードゲームの戦略獲得におけるAIの構造や入出力の表現方法が紹介される。また、講演中には日本将棋連盟女流二段で株式会社ねこまど代表の北尾まどか氏が、モリカAIとの対戦デモを実施する予定だ。
![]() そもそもビデオゲームの戦略獲得を目指すモリカトロンが、なぜアナログなボードゲームのAIを開発しているのか。森川氏によると、ビデオゲームを対象にAIを開発するには、実際にAIを組み込むまでの作業量が膨大になってしまうとのこと。また、テスト用のゲームを用意した場合、AIの賢さを測る客観的な査定が困難になってしまうという問題がある。
そもそもビデオゲームの戦略獲得を目指すモリカトロンが、なぜアナログなボードゲームのAIを開発しているのか。森川氏によると、ビデオゲームを対象にAIを開発するには、実際にAIを組み込むまでの作業量が膨大になってしまうとのこと。また、テスト用のゲームを用意した場合、AIの賢さを測る客観的な査定が困難になってしまうという問題がある。
さらに、権利上の理由から既存のビデオゲームを対象に開発を進めることは現実的ではない。こうした事情から、障壁の少ないボードゲームを足がかりにしたのだという。同社は、ボードゲームにおけるAIの戦略獲得のノウハウを、ビデオゲームへ応用することを想定している。
![]()
ボードゲームのカテゴリーは、完全情報ゲームと不完全情報ゲーム、運が絡む不確定要素の有無、そして二人か多人数かによって、全部で8種類に分類される。これまでAlphaZeroが驚異的なスピードで人間プレイヤーの実力を凌駕したオセロ、チェス、将棋、囲碁は、このうちの「二人完全情報確定ゲーム」に該当する。AIによる学習は、これら二人完全情報確定ゲームがもっとも容易とされており、ここから不完全情報、不確定要素、多人数向けと複雑さを増すごとに、学習難度も比例して上昇していくのだという。
![]()
二人完全情報確定ゲームであれば、同一アルゴリズムと同一ネットワークを使用して、ゲーム固有の人間の知識やデータなしで、まったくの白紙状態から自己対戦で強化できる点が特徴だ。囲碁のほかにチェスや将棋もマスターできるという強みがある。
モリカAIは、このAlphaZeroをベースに、AlphaGo Zeroの手法に手を加え、多人数ゲームに対応させたゲームAIだ。不完全情報および不確定ゲームに対応している。また、同時に、Webアプリ化も進めており、一般の人が学習済みAIとプレイ可能な環境を作っている。(CEDEC講演後、一般公開予定)コードはPython 3で書かれており、フレームワークにはTensorflow、keras、Pytorchが使われている。
AlphaZeroをベースに採用した理由について、二人完全情報確定ゲーム以外のボードゲーム全般へ応用できる可能性が期待できるからだと、森川氏は語る。前述したように、AlphaZeroには完全情報ゲームの学習成果において大きな実績がある。また、多くの研究者たちによるサンプルコードなど、研究に応用できる既存のリソースが豊富に存在することも大きい。モリカトロンは、AlphaZeroから単一のゲームに特化した技術ではなく、汎用性の高いモデルが作れるのではないかと考えているという。
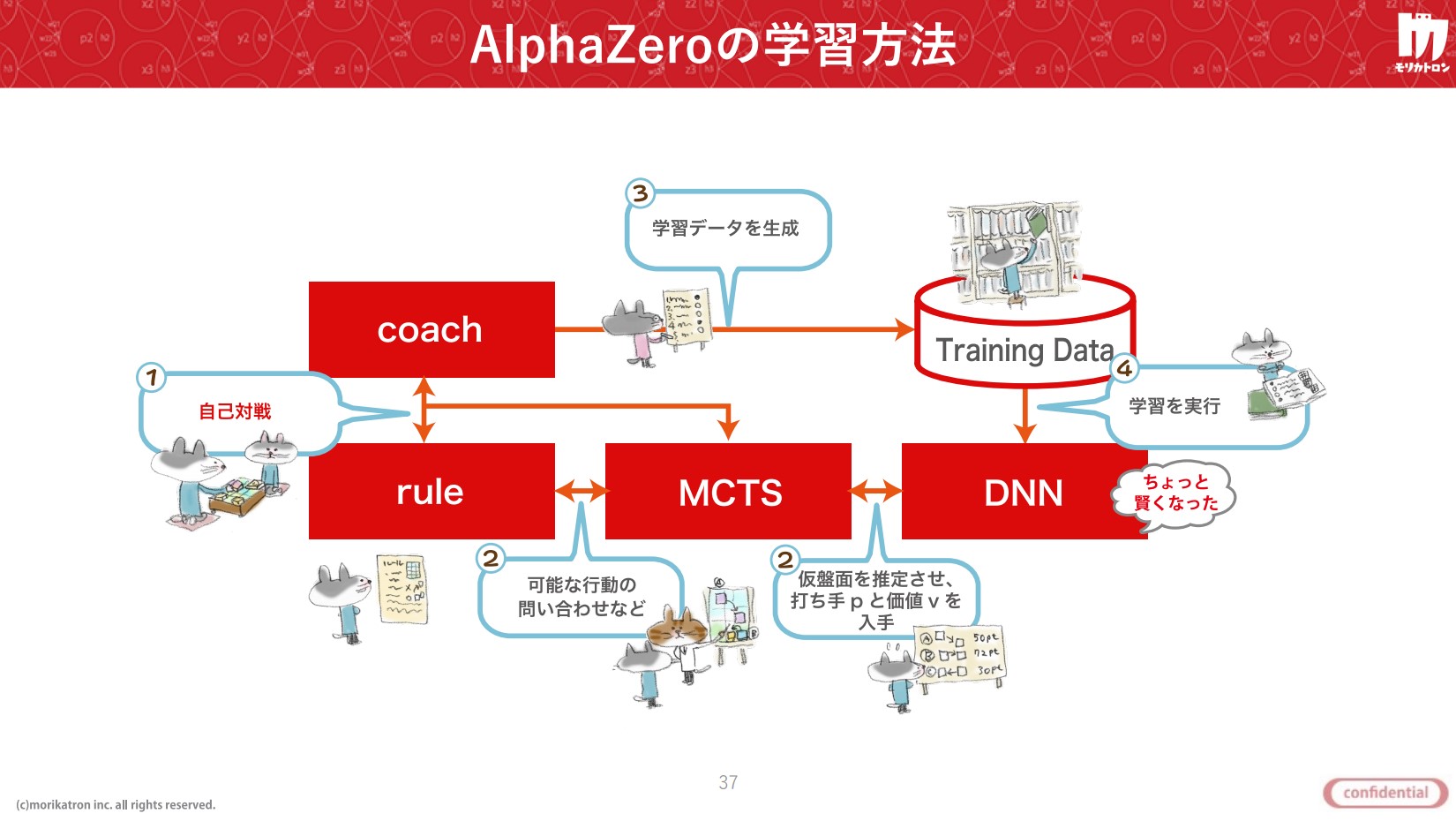
その驚異的な学習効率の印象に反して、AlphaZeroの構造はいたってシンプルだ。まず、ボード・行動・進行の管理といったゲームのルールを定義する。次に、このルールに従ってAIが自身の分身と対局する。それぞれの手は、モンテカルロ木探索によって無数の可能性の中から最善と判断されたものが選択される。
このプロセスが決着するまで繰り返され、その結果から学習データが生成される。このデータをディープニューラルネットワークによって機械学習させるという仕組みだ。すると次の自己対局では、前回の深層学習で得たデータを基にそれぞれの手が決定される。このループを何千、何万回と繰り返すことで、AIはより有効な戦略を自ら生み出していく。
![]()
一方、選択可能な手が増えるほどツリーサーチにかかる時間が増加するため、ゲームによっては学習のループに膨大な計算資源が必要となる。AlphaZeroが発表された際の論文では、セルフプレイに5000個の第1世代TPU、ディープニューラルネットワークの学習に16個の第2世代TPUが使われていた。一般的な企業や個人が有するPCスペックで同じ計算をこなそうとすると、短くて半年以上、ゲームによっては10年以上の時間を要してしまうという。
モリカトロンは、一部の企業や団体のみがアクセスできるスーパーコンピューターのような環境がなくとも、平均的な計算資源で利用できるAIモデルの設計を目指している。その課題をクリアするために、モリカAIの学習プロセスではディープニューラルネットワークのボディやモンテカルロ木探索の回数、深層学習を実行する前の自己対戦回数などに、大幅な軽量化を施したのだという。
![]()
たとえば、AlphaZeroが1手につき800回実行するツリーサーチを、モリカAIは25回から50回の範囲に留めている。また、すべての自己対戦を毎回学習するのではなく、対局データは100戦ごとにまとめてディープニューラルネットワークへ送られるといった具合だ。
![]()
その強さは、5段階の尺度で計測されている。ランダムプレイヤーに勝ち越せないレベル1、ランダムプレイヤーに勝ち越せるレベル2、ルールを覚えたばかりの人間に勝ち越せるレベル3、ゲームを熟知した人間に勝ち越せるレベル4、そしてプロ級の人間に勝ち越せるレベル5だ。なお、ここでのランダムプレイヤーとは、ゲームルールの範疇で無作為な選択肢でプレイしている状態を指す。
現状のモリカAIは、二人完全情報確定ゲームではすでにレベル5に到達しているものの、不確定ゲームではほとんどがレベル3、さらに不完全情報ゲームとなるとレベル2の壁を越えられていないという。前述したボードゲームカテゴリーによる学習難度の違いがはっきりと分かるだろう。ここには、相手プレイヤーの手の内が把握できない不完全情報ゲームならではの課題もあるようだ。たとえば、AIは嘘をつくことも嘘を見抜くこともできないので、人間が得意とするブラフ戦略にまんまと引っかかってしまうのだという。
![]()
CEDECの当日には、チーフエンジニアの松原氏によるモリカAIのさらに詳細な技術解説や計算資源の説明にくわえて、現状の問題点や具体的な対策方法が語られる。特に、モリカトロンの目指す汎用性の高いゲームAIの完成には、サイコロのような運要素への対応はもちろん、AIが人間の意図を読み取れるようになるという最大の課題をクリアしなければならないと、森川氏は指摘する。最新の研究成果では、従来の学習プロセスの枠を越えた新たなアプローチの進展が期待される。
2017年に誕生したDeepMind社の「AlphaZero」は、完全な白紙状態から自己対局のみによって、それら3つのゲームの戦略を学習し、わずか2時間で将棋、4時間でチェスの世界一に到達した。さらに、自身の前身である世界最強の囲碁AI「AlphaGo Zero」を打ち負かすまでに要した時間は、たったの8時間だった。
同年、日本初のゲームAI開発の専門企業として誕生したモリカトロン株式会社は、このAlphaZeroをベースに、完全情報ゲームに限らないゲームへ対応できる汎用型ボードゲームAIの研究に挑んでいる。ゲームという料理に合うAIというワインを選ぶ「AIソムリエ」を謳う同社は、教師なし学習の利点と将来性を検証することで、AIによる自律的な学習がゲーム開発業務にもたらす可能性やメリットを追求している。
その最終目標は、ビデオゲームの戦略獲得だ。9月4日からパシフィコ横浜で開催される国内最大のゲーム開発者向け技術交流会CEDECを前に、AIによる自律的な戦略獲得のノウハウを研究するモリカトロンの開発現場を取材した。
■なぜボードゲームのAIを作ろうと考えたのか
9月6日に予定されているCEDECのレギュラーセッション「AIは自分でボードゲームの勝ち方を見つけられるか?」には、モリカトロンAI研究所の所長である森川幸人氏(写真)、同研究所のチーフエンジニア松原卓二氏、同社取締役の成沢理恵氏が登壇する。このセッションでは、AlphaZeroをベースに開発された同社オリジナルのAIモデル「モリカAI」を使ったボードゲーム学習の仕組みが披露されるほか、ボードゲームの戦略獲得におけるAIの構造や入出力の表現方法が紹介される。また、講演中には日本将棋連盟女流二段で株式会社ねこまど代表の北尾まどか氏が、モリカAIとの対戦デモを実施する予定だ。

さらに、権利上の理由から既存のビデオゲームを対象に開発を進めることは現実的ではない。こうした事情から、障壁の少ないボードゲームを足がかりにしたのだという。同社は、ボードゲームにおけるAIの戦略獲得のノウハウを、ビデオゲームへ応用することを想定している。
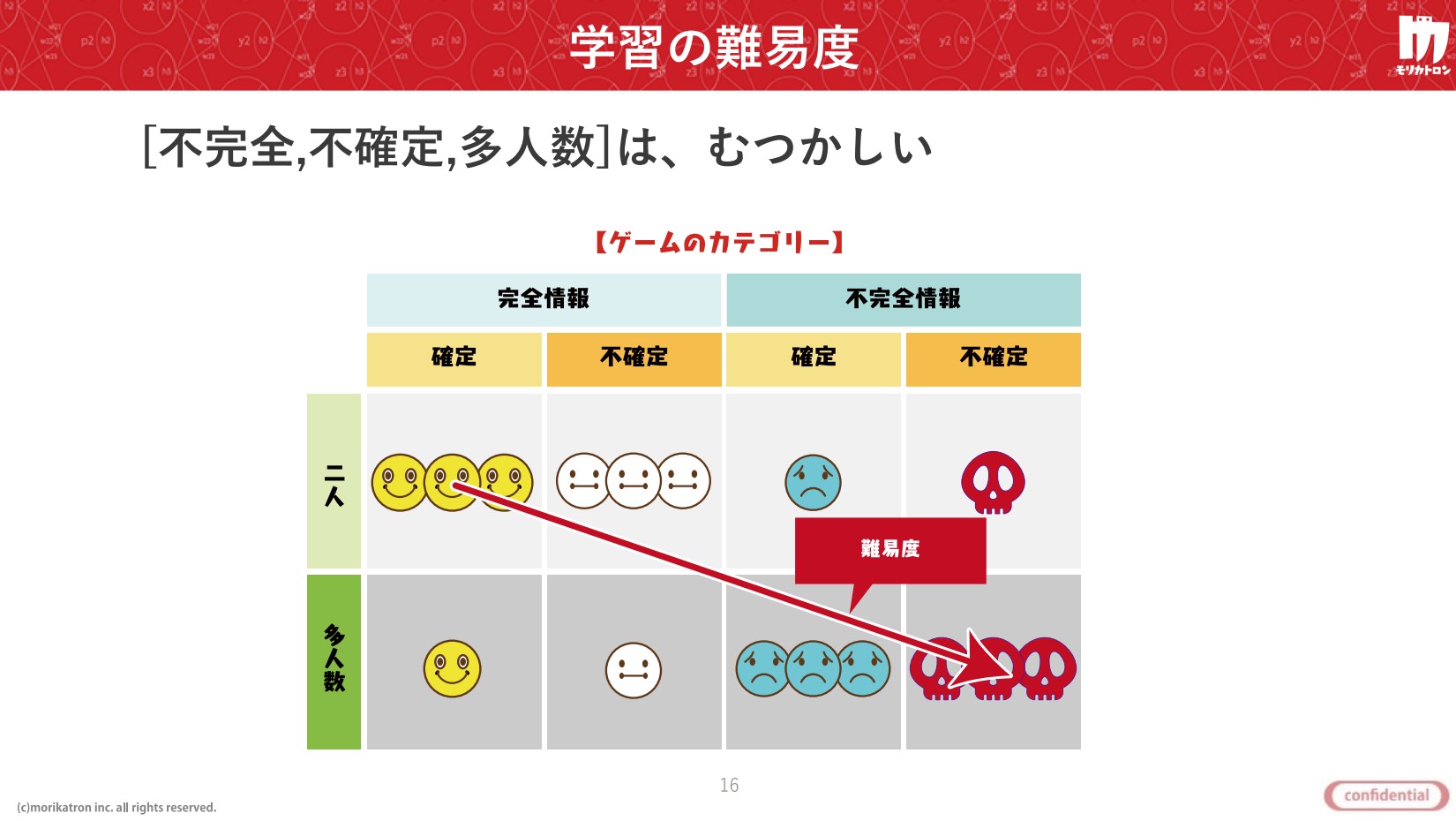
ボードゲームのカテゴリーは、完全情報ゲームと不完全情報ゲーム、運が絡む不確定要素の有無、そして二人か多人数かによって、全部で8種類に分類される。これまでAlphaZeroが驚異的なスピードで人間プレイヤーの実力を凌駕したオセロ、チェス、将棋、囲碁は、このうちの「二人完全情報確定ゲーム」に該当する。AIによる学習は、これら二人完全情報確定ゲームがもっとも容易とされており、ここから不完全情報、不確定要素、多人数向けと複雑さを増すごとに、学習難度も比例して上昇していくのだという。
■なぜAlphaZeroを土台として選んだのか
モリカトロンが研究の土台に選んだAlphaZeroとは、Google傘下のDeepMind社が2015年に開発した囲碁プログラム「AlphaGo」と、その改良版である「AlphaGo Zero」を、さらに汎用化したAIである。そのアルゴリズムには、従来のAIに一般的であったアルファ・ベータ探索ではなく、モンテカルロ木探索とディープラーニングが用いられている。
二人完全情報確定ゲームであれば、同一アルゴリズムと同一ネットワークを使用して、ゲーム固有の人間の知識やデータなしで、まったくの白紙状態から自己対戦で強化できる点が特徴だ。囲碁のほかにチェスや将棋もマスターできるという強みがある。
モリカAIは、このAlphaZeroをベースに、AlphaGo Zeroの手法に手を加え、多人数ゲームに対応させたゲームAIだ。不完全情報および不確定ゲームに対応している。また、同時に、Webアプリ化も進めており、一般の人が学習済みAIとプレイ可能な環境を作っている。(CEDEC講演後、一般公開予定)コードはPython 3で書かれており、フレームワークにはTensorflow、keras、Pytorchが使われている。
AlphaZeroをベースに採用した理由について、二人完全情報確定ゲーム以外のボードゲーム全般へ応用できる可能性が期待できるからだと、森川氏は語る。前述したように、AlphaZeroには完全情報ゲームの学習成果において大きな実績がある。また、多くの研究者たちによるサンプルコードなど、研究に応用できる既存のリソースが豊富に存在することも大きい。モリカトロンは、AlphaZeroから単一のゲームに特化した技術ではなく、汎用性の高いモデルが作れるのではないかと考えているという。
■AlphaZeroの仕組みとモリカAIの工夫
その驚異的な学習効率の印象に反して、AlphaZeroの構造はいたってシンプルだ。まず、ボード・行動・進行の管理といったゲームのルールを定義する。次に、このルールに従ってAIが自身の分身と対局する。それぞれの手は、モンテカルロ木探索によって無数の可能性の中から最善と判断されたものが選択される。
このプロセスが決着するまで繰り返され、その結果から学習データが生成される。このデータをディープニューラルネットワークによって機械学習させるという仕組みだ。すると次の自己対局では、前回の深層学習で得たデータを基にそれぞれの手が決定される。このループを何千、何万回と繰り返すことで、AIはより有効な戦略を自ら生み出していく。
一方、選択可能な手が増えるほどツリーサーチにかかる時間が増加するため、ゲームによっては学習のループに膨大な計算資源が必要となる。AlphaZeroが発表された際の論文では、セルフプレイに5000個の第1世代TPU、ディープニューラルネットワークの学習に16個の第2世代TPUが使われていた。一般的な企業や個人が有するPCスペックで同じ計算をこなそうとすると、短くて半年以上、ゲームによっては10年以上の時間を要してしまうという。
モリカトロンは、一部の企業や団体のみがアクセスできるスーパーコンピューターのような環境がなくとも、平均的な計算資源で利用できるAIモデルの設計を目指している。その課題をクリアするために、モリカAIの学習プロセスではディープニューラルネットワークのボディやモンテカルロ木探索の回数、深層学習を実行する前の自己対戦回数などに、大幅な軽量化を施したのだという。
たとえば、AlphaZeroが1手につき800回実行するツリーサーチを、モリカAIは25回から50回の範囲に留めている。また、すべての自己対戦を毎回学習するのではなく、対局データは100戦ごとにまとめてディープニューラルネットワークへ送られるといった具合だ。
■モリカAIの実力と今後の課題
モリカAIは現在までに、完全情報ゲームでは「どうぶつしょうぎ」「ゴブレット・ゴブラーズ」「立体四目並べ」「サイコロ将棋」「四人オセロ」「キュージェット」、不完全情報ゲームでは「ガイスター」「バトルライン」「クイビット!」「ハゲタカのえじき」「すずめ雀」を学習している。
その強さは、5段階の尺度で計測されている。ランダムプレイヤーに勝ち越せないレベル1、ランダムプレイヤーに勝ち越せるレベル2、ルールを覚えたばかりの人間に勝ち越せるレベル3、ゲームを熟知した人間に勝ち越せるレベル4、そしてプロ級の人間に勝ち越せるレベル5だ。なお、ここでのランダムプレイヤーとは、ゲームルールの範疇で無作為な選択肢でプレイしている状態を指す。
現状のモリカAIは、二人完全情報確定ゲームではすでにレベル5に到達しているものの、不確定ゲームではほとんどがレベル3、さらに不完全情報ゲームとなるとレベル2の壁を越えられていないという。前述したボードゲームカテゴリーによる学習難度の違いがはっきりと分かるだろう。ここには、相手プレイヤーの手の内が把握できない不完全情報ゲームならではの課題もあるようだ。たとえば、AIは嘘をつくことも嘘を見抜くこともできないので、人間が得意とするブラフ戦略にまんまと引っかかってしまうのだという。

CEDECの当日には、チーフエンジニアの松原氏によるモリカAIのさらに詳細な技術解説や計算資源の説明にくわえて、現状の問題点や具体的な対策方法が語られる。特に、モリカトロンの目指す汎用性の高いゲームAIの完成には、サイコロのような運要素への対応はもちろん、AIが人間の意図を読み取れるようになるという最大の課題をクリアしなければならないと、森川氏は指摘する。最新の研究成果では、従来の学習プロセスの枠を越えた新たなアプローチの進展が期待される。
著者:Ritsuko Kawai / 河合律子


