
 gloopsは、6月11日、企業のデータ分析、マーケティング担当者を対象としたビッグデータ分析・活用セミナー「2億PV/日を支えるgloopsのビッグデータ分析」を東京都内のgloops本社で開催した。
gloopsは、6月11日、企業のデータ分析、マーケティング担当者を対象としたビッグデータ分析・活用セミナー「2億PV/日を支えるgloopsのビッグデータ分析」を東京都内のgloops本社で開催した。gloopsでは累計40タイトルのソーシャルゲームを配信しており、延べ登録者数は3000万人を超えている。今回のセミナーでは、3000万人のユーザーから発生する膨大なデータを効率よく処理・分析し、ソーシャルゲームの運営に活用しているのかが具体的な事例を交えて紹介された。本稿では、そのセミナーの模様をお伝えしておこう。昨年この時期に実施したgloopsのデータマイニングアナリストの伊藤氏のインタビュー記事も合わせて読まれると面白いかと思う(関連記事)。
■データマイニンググループのミッション
今回、講師としてソーシャルゲーム事業本部システム統括部データマイニンググループのアナリスト山本真吾氏(写真)が登壇した。山本氏は、自身の経歴と会社の概要、事業内容を簡単に紹介した後、gloopsにおけるデータマイニンググループのミッションについて「面白さ」を定量的に把握してわかりやすく表現し、そこから得られる知見をもって提案・実行することにあると説明した。



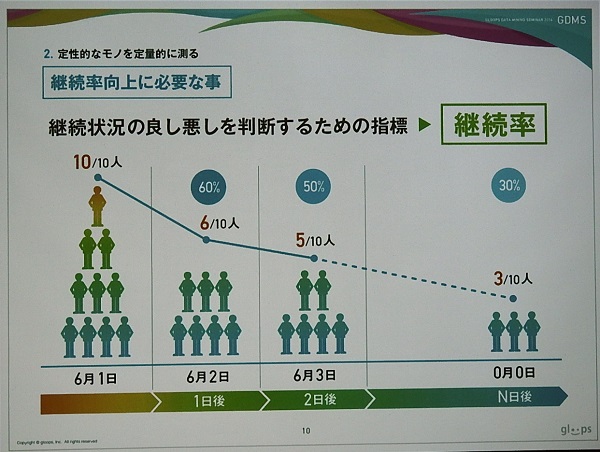
その指標として「継続率」がある。継続率とは、例えば、6月1日時点で10人が会員登録し、翌日には6人が継続したとなると、1日後継続率は60%、そして翌日には5人だと2日後継続率が50%となる。この継続率をいかに向上させるかが運営上、重要になる。そのためにゲームの問題点や離脱ポイントを見つけ出し、改善策を模索していくことになる。
■データ分析の流れ
続いて、データ分析の流れの一例を紹介した。その流れは以下のようになる(実際にはこれ以外にも様々な分析枠組みがあるそうである)。これに沿って説明が行われた。
1.顧客を特徴別に分類する
2.ターゲットを決める
3.ターゲットの行動を見る
4.行動から離脱要因について仮説を立てる
5.仮説を統計的に検証する
1.顧客を特徴別に分類する
まず、3000万人を超える累計登録者がいると、長期間プレイする上級者や、移動時間に隙間時間に楽しむ人、ゲームを始めたばかりの人まで多種多様なユーザーが存在し、その楽しみ方やゲームに対する感じ方も異なってくる。よって、顧客を特徴別に分類したうえで分析を行い、ゲームの問題点を探っていくことになる。
その分類方法として、BU/FUを紹介した。これはDAUを過去30日のログイン日数で分類するもので、ログイン日数が多いユーザーを「BU」(Base User)、逆に少ないユーザーを「FU」(Follow User)として分類していく。gloopsでは、ログイン日数が1日のHFUから26日以上ログインするHBUまで6段階に分類している。

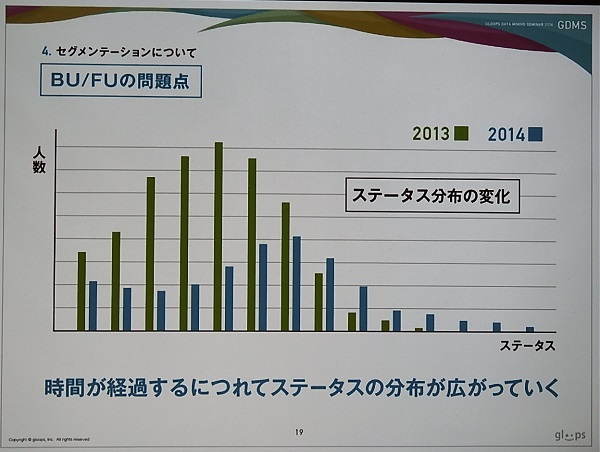
ただし、これには大きな問題がある。それは時間が経過するに従って、同じログイン日数でも成長速度の速い人、遅い人に分かれるなど、ユーザーに多様性が生じてくることだ。これを示したのが下のスライドとなる。これはあるゲームの実例で、2013年と2014年のステータスと人数の分布をみると、2014年の方がユーザー分布が広がったことがわかる。したがって、ログイン日数だけで分類することは適切ではなくなる。
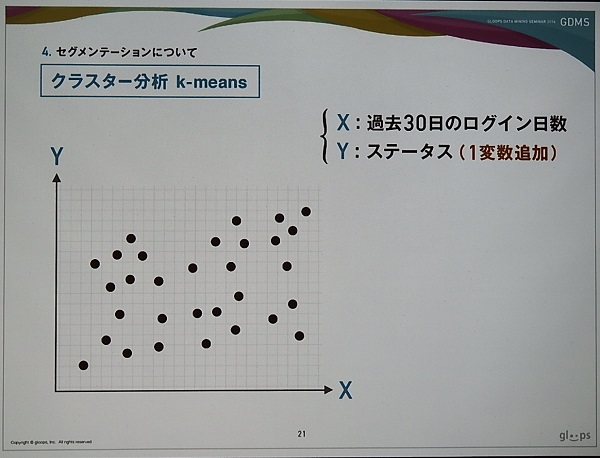
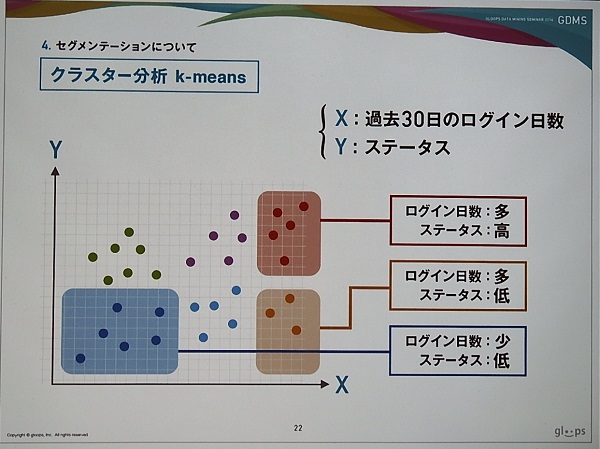
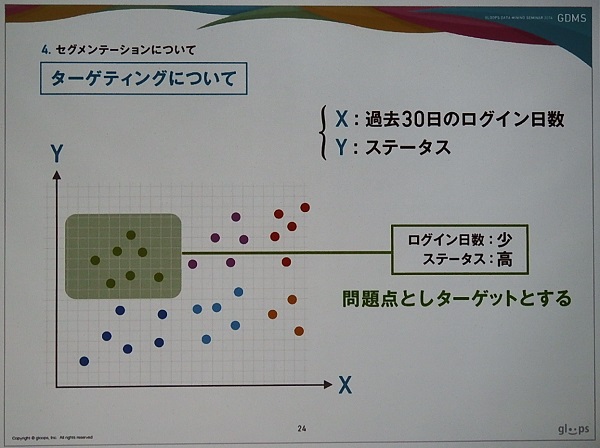
そこでログイン日数以外の変数を組み入れて分類を行う必要が出てくる。その一つとしてステータスがある。下のスライドは、X軸に過去30日のログイン日数、Y軸にステータスを追加し、プロットしたグラフである。これをクラスター分析(k-means)を使うと、ログイン日数が多くてステータスの高いユーザー層、ログイン日数が多くてステータスの低いユーザー層などと分類できる。
2.ターゲットを決める
分類したクラスターの中で問題のありそうなクラスターとして、ログイン日数が少なくステータスが高いユーザー層をピックアップした。このユーザー層を過去、積極的に遊んでいて、現在は遊ぶ頻度が減ってしまったユーザー層としている。ただ新規ユーザーが猛スピードでステータスを上げたケースも想定されるため、実際は6、7種類の指標で分類するそうだ。
3.ターゲットの行動を見る
ターゲットを決めたら、そのユーザーがゲーム内でどういった行動を取っているかを把握する必要がある。gloopsでは、1日あたり1コンテンツで2000万~1億PV、履歴データでは500万~1000万件のデータを取っている。この膨大なデータをいかに効率的に処理するかが問題となる。

gloopsでは、行動履歴データについては、SQLサーバーとhadoopでそれぞれ保存している。そしてデータ分析にあたって一度、データをhadoopに集約し、PigやHiveといったスクリプトを使って加工し、Rを介して出力する、といった処理を行っているとのこと。
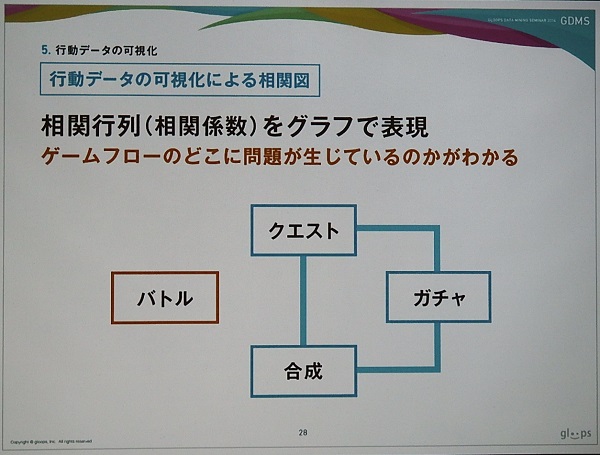
出力した行動データを可視化するため、相関行列(相関係数)をグラフとして表現している。クエストで積極的に遊ぶユーザーはガチャや合成も積極的に行うといった状況で、「バトル」であまり遊んでいない状況にあることが伺える。つまり、バトルに何か問題があるのだ。
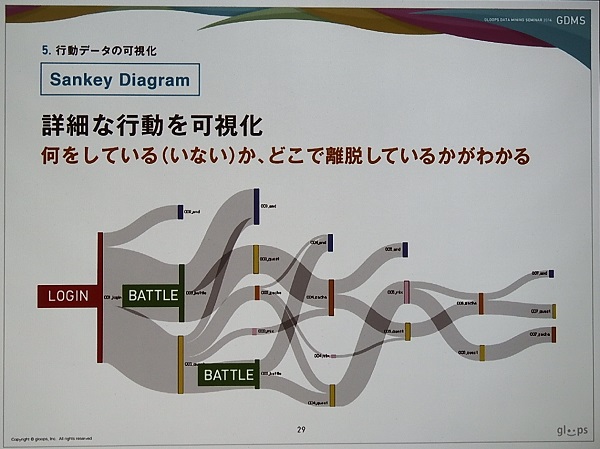
さらに「Sankey Diagram」を用いて、ユーザーの行動を詳細に可視化しているとのこと。この見方は、左側からユーザーがなにをしている(いない)かを示すもので、下の事例ではログインした後、半分がバトルに移動したものの、多くがバトルをやめてしまった、あるいはログアウトしてしまったことを示している。バトルに問題があるという判断となった。
4.行動から離脱要因について仮説を立てる
5.仮説を統計的に検証する
バトルに何か問題があるのはわかったが、何が問題なのか。様々な可能性の中から離脱と思われる要因を仮説として、
(1)「俺TUEEEEE」感がなくて離脱した…自分が強くなると相手が強くなる仕様となっており、強くなった実感が持てない。つまりバトルの仕組みに問題がある
(2)アイテムが不足して離脱した…課金ありきのバランスになっていることに嫌気をさしたのではないか。
を立てて、統計的に検証した。
そのために統計モデルをつくり、実際のデータを使って検証する。今回は、継続・離脱のように1と0を目的変数とし、説明変数と線形結合している「ロジスティック回帰分析」を使用した。この利点は、説明変数が目的変数にどういった影響を与えているのかが分かる点で、金融機関での信用リスクの評価などにも使われているという。

統計モデルで検証したところ、仮説1の影響が大きいことが判明し、逆に仮説2の影響は小さいことがわかった。「マッチングロジック」の変更を行い、より成長が感じられるようにしたことで、ユーザーの継続率が向上したとのこと。gloopsで実際にあった事例だそうである。

■分析だけでなく改善策を提案しその結果を測るまでが仕事
データマイニングの仕事は、膨大なデータを使って分析するだけでなく、改善策を提案し、その結果を測るまでが仕事だ。要は、分析それ自体が目的となってはいけない。そこで導かれた改善策を提案し、それに基づいてゲームの改修を行ってもらう必要がある。
そのためには、企画やデザイナー、プログラマーといったチームのメンバーに問題点や改善案を理解してもらう必要がある。山本氏は、数字や文字による資料ではなく、問題点や改善策を図で表現して直感的に理解できるようにしているそうだ(実際は図とデータをセットで提示しているとのこと)。逆に数字や文字データの羅列など直感的にわかりづらい資料は、チーム内で認識のズレを生み出しやすいと考えているという。
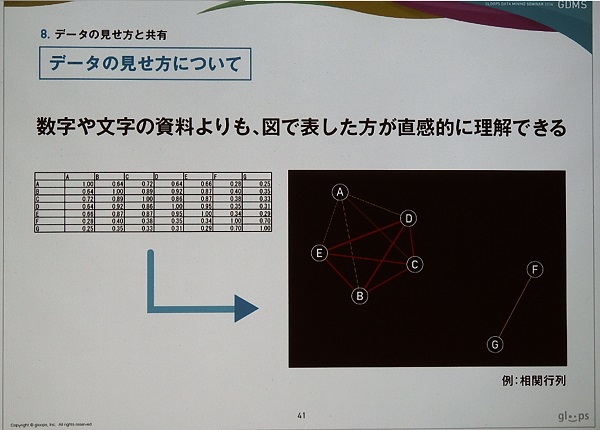
さらにグループ内での共有方法は、
(1)直接話して伝える…重要な情報ほど直接話している
(2)メール…毎日配信する情報に使う
(3)RやPHP、Java…ツールを開発し、グループのメンバーがいつでも確認できるようにする。
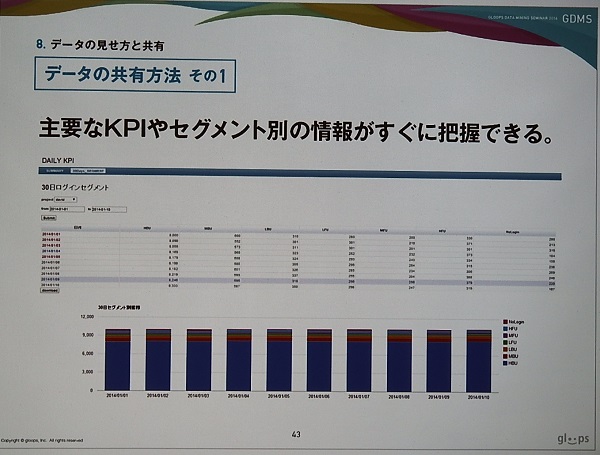
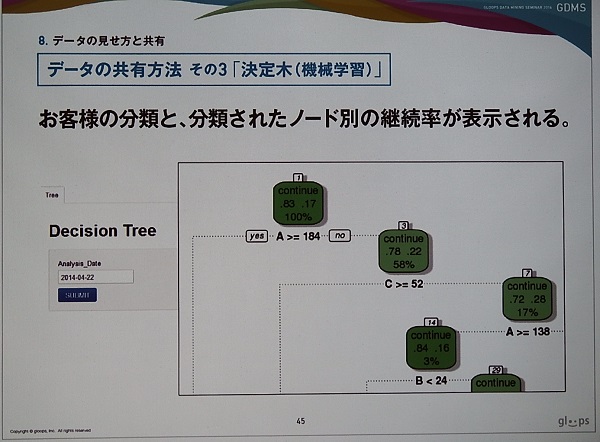
がある。gloopsで実際に開発されたツール群のデモも行われた。

■ボタンを追加するだけで継続率が向上
最後に実際の改修事例の紹介を行った。『ドラゴンエクリプス』の事例と思われるが、チュートリアル終了後に離脱するユーザーが続出する問題があったそうだ。その際、山本氏は、チュートリアル終了後の導線に問題があると考え、調査したところ、クエストに参加できているユーザーは継続的にプレイしていることが判明し、クエストに誘導できれば継続率が向上するはずだと考えたという。

そこで下のスライドのように、チュートリアル終了画面の下に「冒険(クエスト)へ」というボタンを追加した。これだけのことだが、「クエストに参加するユーザーが増えて継続率が向上した」(山本氏)。

改善前と後のユーザーの行動を示した「Sankey Diagram」は以下のようになる。上の改善前はチュートリアル終了後、ギフト画面やマイページに移動し、ゲームの本線であるクエストに移動していない。しかし、改修後を示すその下のスライドでは、クエストへの流入が増加したことが分かる。
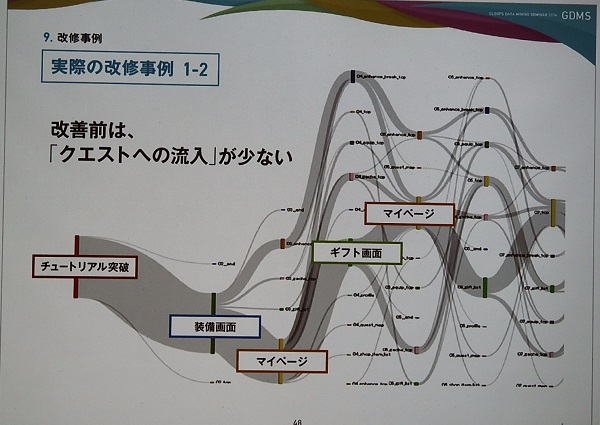
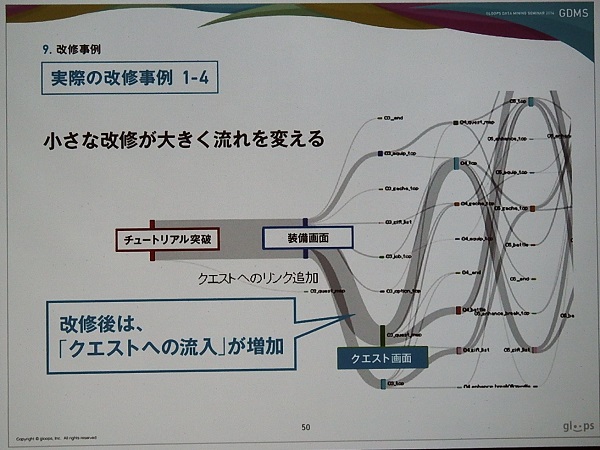
山本氏は、「数字のデータを見るだけではこの改修は行えなかった。お客様の行動の分岐は非常に多く、とてもひとつずつチェックできない。パッと見て直感的に分かる表現方法にしたことで問題を発見することができ、小さな改修で大きな流れを変えることができた。それを示すことができた良い事例だった」と振り返り、直感的に表現することの重要性を強調した。
まとめとして、「お客様の声はデータ様が知っている。しかし、その声はわかりにくい。データマイニングが仲介することで、データ様の声、つまりお客様の声をみんなが分かるようになる。データマイニングの役割は、データ様の声をわかりやすく正確に早く伝えることにある」と語り、講演を締めくくった。
なお、現在、gloopsでは、データマイニングで働く「勇者」を絶賛募集しているとのこと。興味のある方は同社採用サイトで詳細を確認してほしい。




